Analyser XML en Javascript avec DOMParser
1. DOMParser
DOMParser est une interface qui permet d'analyser le code source XML ou HTML d'une String dans un document DOM Document.
Constructor:
// Create a DOMParser
var parser = new DOMParser();
Analysez le code source XML/HTML dans un DOM Document :
var parser = new DOMParser();
// XMLDocument object:
var doc1 = parser.parseFromString(xmlString, "text/xml");
// Document object:
var doc2 = parser.parseFromString(xmlString, "text/html");DOMParser ne peut pas analyser la source XML si cette source n'est pas valide mais elle ne déclenche pas d'erreur. Au lieu de cela, il renvoie un objet Document contenant des informations erronées. Et cet objet Document a un contenu légèrement différent avec différents navigateurs mais contient toujours une étiquette (tag) <parsererror>.
...
<parsererror xmlns="http://www.mozilla.org/newlayout/xml/parsererror.xml">
(error description)
<sourcetext>(a snippet of the source XML)</sourcetext>
</parsererror>
...Vous devriez écrire une fonction utilitaire pour analyser XML. Cette fonction lance les erreurs si XML n'est pas valide.
Utility Function
// Utility function:
// Return XMLDocument, or throw an Error!
function parseXML(xmlString) {
var parser = new DOMParser();
// Parse a simple Invalid XML source to get namespace of <parsererror>:
var docError = parser.parseFromString('INVALID', 'text/xml');
var parsererrorNS = docError.getElementsByTagName("parsererror")[0].namespaceURI;
// Parse xmlString:
// (XMLDocument object)
var doc = parser.parseFromString(xmlString, 'text/xml');
if (doc.getElementsByTagNameNS(parsererrorNS, 'parsererror').length > 0) {
throw new Error('Error parsing XML');
}
return doc;
}Remarque : En utilisant XMLHttpRequest pour lire une source de données XML depuis une URL, vous pouvez recevoir un objet XMLDocument.
2. Exemple de DOMParser
DOMParser va analyser un XML dans une arborescence DOM (DOM Tree) (Comme l'illustration ci-dessous). Vous avez besoin les API qui ont fournit par le modèle DOM afin d'extraire des données nécessaires.
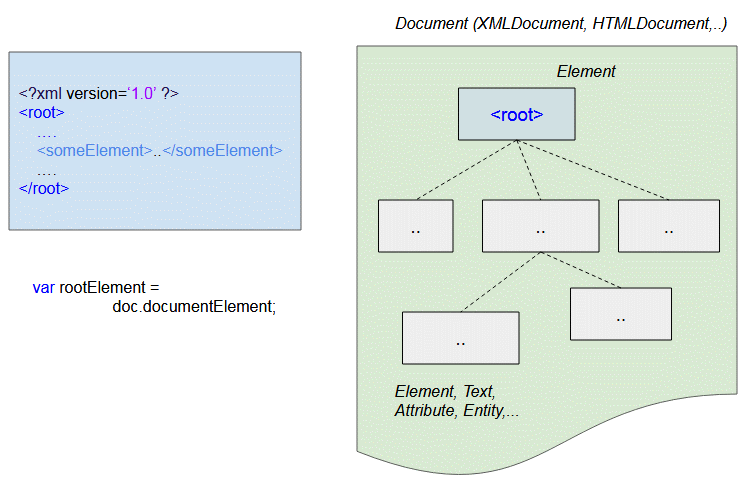
domparser-example.html
<!DOCTYPE html>
<html>
<head>
<title>DOMParser Example</title>
<meta charset="UTF-8">
<script src="domparser-example.js"></script>
</head>
<body>
<h3>DOMParser example</h3>
<a href="">Reset</a> <br><br>
<button onclick = "clickHandler(event)">Click Me</button>
<br><br>
<textarea id="textarea-log" rows="15" style="width:100%;"></textarea>
</body>
</html>domparser-example.js
// Utility function:
// Return XMLDocument, or throw an Error!
function parseXML(xmlString) {
var parser = new DOMParser();
// Parse a simple Invalid XML source to get namespace of <parsererror>:
var docError = parser.parseFromString('INVALID', 'text/xml');
var parsererrorNS = docError.getElementsByTagName("parsererror")[0].namespaceURI;
// Parse xmlString:
// (XMLDocument object)
var doc = parser.parseFromString(xmlString, 'text/xml');
if (doc.getElementsByTagNameNS(parsererrorNS, 'parsererror').length > 0) {
throw new Error('Error parsing XML');
}
return doc;
}
// XML String:
var xmlString = "<?xml version = '1.0'?>" +
"<class> " +
" <student rollNo = '393'> " +
" <fullName>Putin</fullName> " +
" <nickName>putin</nickName> " +
" <marks>95</marks> " +
" </student> "
+
" <student rollNo = '493'> " +
" <fullName>Trump</fullName> " +
" <nickName>trump</nickName> " +
" <marks>90</marks> " +
" </student> "
+
" <student rollNo = '593'> " +
" <fullName>Kim</fullName> " +
" <nickName>kim</nickName> " +
" <marks>85</marks> " +
" </student> " +
"</class> ";
function clickHandler(evt) {
console.log(xmlString);
var doc;
try {
// XMLDocument object:
doc = parseXML(xmlString);
console.log(doc.documentElement);
} catch (e) {
alert(e);
return;
}
resetLog();
// Element object. <--> <class>
var rootElement = doc.documentElement;
//
var children = rootElement.childNodes;
for(var i =0; i< children.length; i++) {
var child = children[i];
// <studen> Element
if(child.nodeType == Node.ELEMENT_NODE) {
var rollNo = child.getAttribute("rollNo");
var fullNameElement = child.getElementsByTagName("fullName")[0];
var nickNameElement = child.getElementsByTagName("nickName")[0];
var marksElement = child.getElementsByTagName("marks")[0];
var fullName = fullNameElement.textContent;
var nickName = nickNameElement.textContent;
var marks = marksElement.textContent;
appendLog("rollNo: " + rollNo);
appendLog("fullName: " + fullName);
appendLog("nickName: " + nickName);
appendLog("marks: " + marks);
}
}
}
function resetLog() {
document.getElementById('textarea-log').value = "";
}
function appendLog(msg) {
document.getElementById('textarea-log').value += "\n" + msg;
}-
Voir plus :
Tutoriels de programmation ECMAScript, Javascript
- Introduction à Javascript et ECMAScript
- Démarrage rapide avec Javascript
- Boîte de dialogue Alert, Confirm, Prompt en Javascript
- Démarrage rapide avec JavaScript
- Variables dans JavaScript
- Opérations sur les bits
- Les Tableaux (Array) en JavaScript
- Boucles dans JavaScript
- Le Tutoriel de JavaScript Function
- Le Tutoriel de JavaScript Number
- Le Tutoriel de JavaScript Boolean
- Le Tutoriel de JavaScript String
- Le Tutoriel de instruction JavaScript if/else
- Le Tutoriel de instruction JavaScript switch
- Tutoriel de gestion des erreurs JavaScript
- Le Tutoriel de JavaScript Date
- Le Tutoriel de JavaScript Module
- L'histoire des modules en JavaScript
- Fonctions setTimeout et setInterval dans JavaScript
- Le Tutoriel de Javascript Form Validation
- Le Tutoriel de JavaScript Web Cookie
- Mot clé Void dans JavaScript
- Classes et objets dans JavaScript
- Techniques de simulation classe et héritage en JavaScript
- Héritage et polymorphisme dans JavaScript
- Comprendre Duck Typing dans JavaScript
- Le Tutoriel de JavaScript Symbol
- Le Tutoriel de JavaScript Set Collection
- Le Tutoriel de JavaScript Map Collection
- Comprendre JavaScript Iterable et Iterator
- Expression régulière en JavaScript
- Le Tutoriel de JavaScript Promise, Async Await
- Le Tutoriel de Javascript Window
- Le Tutoriel de Javascript Console
- Le Tutoriel de Javascript Screen
- Le Tutoriel de Javascript Navigator
- Le Tutoriel de Javascript Geolocation API
- Le Tutoriel de Javascript Location
- Le Tutoriel de Javascript History API
- Le Tutoriel de Javascript Statusbar
- Le Tutoriel de Javascript Locationbar
- Le Tutoriel de Javascript Scrollbars
- Le Tutoriel de Javascript Menubar
- Le Tutoriel de Javascript JSON
- La gestion des événements en JavaScript
- Le Tutoriel de Javascript MouseEvent
- Le Tutoriel de Javascript WheelEvent
- Le Tutoriel de Javascript KeyboardEvent
- Le Tutoriel de Javascript FocusEvent
- Le Tutoriel de Javascript InputEvent
- Le Tutoriel de Javascript ChangeEvent
- Le Tutoriel de Javascript DragEvent
- Le Tutoriel de Javascript HashChangeEvent
- Le Tutoriel de Javascript URL Encoding
- Le Tutoriel de Javascript FileReader
- Le Tutoriel de Javascript XMLHttpRequest
- Le Tutoriel de Javascript Fetch API
- Analyser XML en Javascript avec DOMParser
- Introduction à Javascript HTML5 Canvas API
- Mettre en évidence le code avec la bibliothèque Javascript de SyntaxHighlighter
- Que sont les polyfills en science de la programmation?
Show More