Le Tutoriel de Java OutputStreamWriter
1. OutputStreamWriter
OutputStreamWriter est une sous-classe de Writer, c'est un pont qui vous permet de convertir un byte stream en un character stream, en d'autres termes, il vous permet de convertir un OutputStream en Writer.
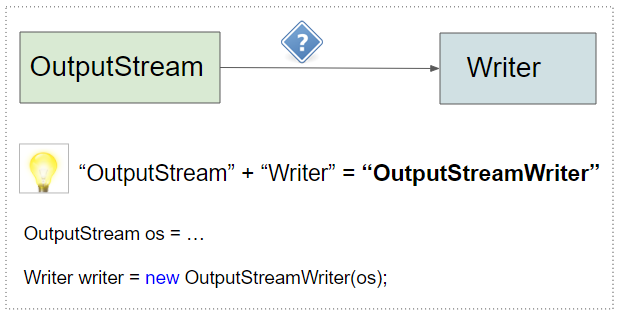
Astuce: Pour convertir un "OutputStream" en un "Writer", il vous suffit de concaténer ces deux mots pour former "OutputStreamWriter" et vous obtiendrez la solution.
OutputStreamWriter constructors
OutputStreamWriter(OutputStream out)
OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out, Charset cs)
OutputStreamWriter(OutputStream out, CharsetEncoder enc)Outre ces méthodes héritées de la superclasse, OutputStreamWriter a quelques autres méthodes qui lui sont propres.
Method | Description |
String getEncoding() | Renvoie le nom du codage de caractères utilisé par OutputStreamWriter. |
2. UTF-16 OutputStreamWriter
UTF-16 est un codage (encoding) assez courant pour le texte chinois ou japonais. Dans cet exemple, on analysera la manière d'écrire un fichier en utilisant le codage UTF-16.
Et voici le contenu à écrire dans le fichier:
JP日本-八洲Dans cet exemple, on utilise UTF-16 OutputStreamWriter pour écrire les caractères dans un fichier, ensuite, on utilise FileInputStream pour lire chaque byte de ce fichier.
OutputStreamWriter_UTF16_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF16_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf16-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-16 File --- ");
write_UTF16_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF16_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_16);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-16 File ---
--- Read File as Binary Stream ---
þ 254
ÿ 255
0
J 74
0
P 80
e 101
å 229
g 103
, 44
0
- 45
Q 81
k 107
m 109
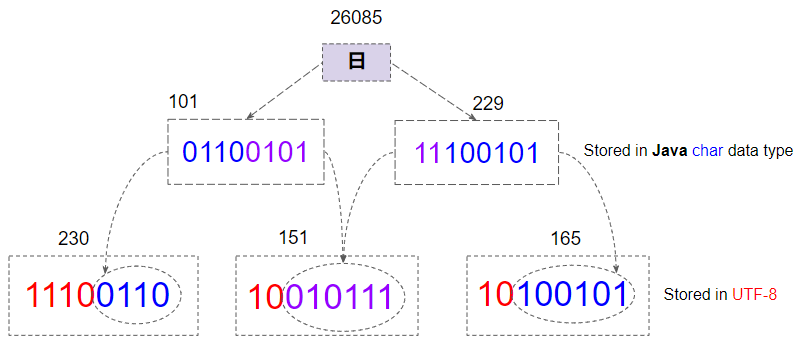
2 50Dans Java, le type de données char a une taille de 2 bytes et UTF-16 est utilisé pour encoder le type String. L'image ci-dessous montre les caractères sur OutputStreamWriter:
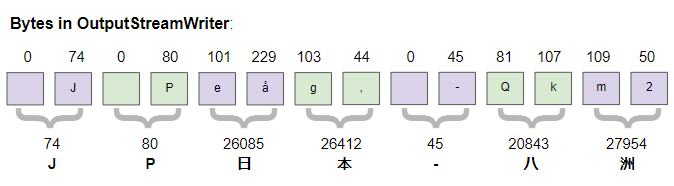
On voit qu'à partir de l'analyse des bytes sur le fichier nouvellement créé: les 2 premiers bytes (254, 255) sont utilisés pour marquer qu'il s'agit d'un texte encodé en UTF-16. Ils sont également connus sous le nom de BOM (Byte Order Mark), les bytes suivants sont les mêmes que les bytes sur OutputStreamWriter.

3. UTF-8 OutputStreamWriter
UTF-8 est l'encodage le plus populaire au monde. Il peut encoder toutes les écritures du monde, y compris les caractères chinois et japonais. À partir de Java5, UTF-8 est l'encodage par défaut pour la lecture et l'écriture de fichiers.
Les fichiers UTF-8 créés par Java n'ont pas de BOM (Byte Order Mark) (les premiers bytes du fichier pour marquer qu'il s'agit d'un fichier UTF-8).
OutputStreamWriter_UTF8_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF8_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf8-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-8 File --- ");
write_UTF8_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF8_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_8);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-8 File ---
--- Read File as Binary Stream ---
J 74
P 80
æ 230
151
¥ 165
æ 230
156
¬ 172
- 45
å 229
133
« 171
æ 230
´ 180
² 178Dans Java, le type de données char a une taille de 2 bytes et UTF-16 est utilisé pour encoder le type String. L'image ci-dessous montre les caractères sur OutputStreamWriter:
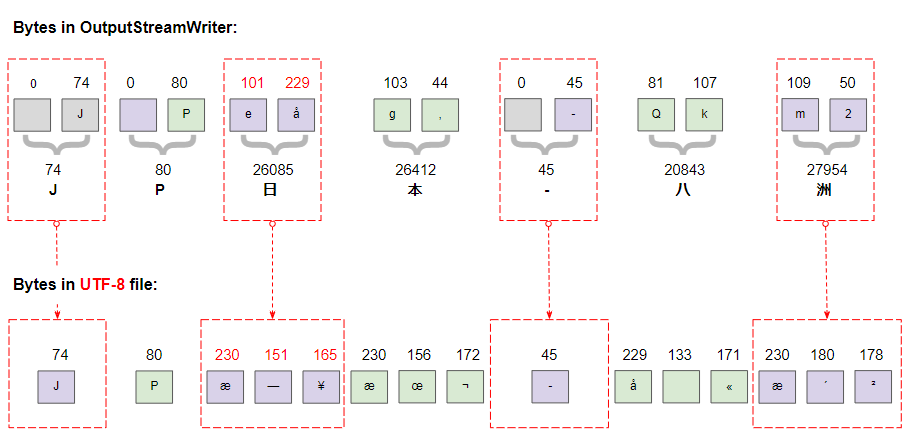
UTF-8 est codé de manière beaucoup plus complexe que UTF-16, il utilise 1, 2, 3 ou 4 bytes pour stocker un caractère. Une analyse détaillée des bytes du fichier UTF-8 nouvellement créé le démontre clairement.
Number of bytes | From | To | Byte 1 | Byte 2 | Byte 3 | Byte 4 | ||
1 | U+0000 | 0 | U+007F | 127 | 0xxxxxxx | |||
2 | U+0080 | 128 | U+07FF | 2047 | 110xxxxx | 10xxxxxx | ||
3 | U+0800 | 2048 | U+FFFF | 65535 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
4 | U+10000 | 65536 | U+10FFFF | 1114111 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Par exemple, le caractère "日" a le code 26085, dans la sphère [2048,65535], UTF-8 a besoin de 3 bytes pour le stocker.
Tutoriels Java IO
- Le Tutoriel de Java CharArrayWriter
- Le Tutoriel de Java FilterReader
- Le Tutoriel de Java FilterWriter
- Le Tutoriel de Java PrintStream
- Le Tutoriel de Java BufferedReader
- Le Tutoriel de Java BufferedWriter
- Le Tutoriel de Java StringReader
- Le Tutoriel de Java StringWriter
- Le Tutoriel de Java PipedReader
- Le Tutoriel de Java LineNumberReader
- Le Tutoriel de Java PushbackReader
- Le Tutoriel de Java PrintWriter
- Tutoriel sur les flux binaires Java IO
- Le Tutoriel de Java IO Character Streams
- Le Tutoriel de Java BufferedOutputStream
- Le Tutoriel de Java ByteArrayOutputStream
- Le Tutoriel de Java DataOutputStream
- Le Tutoriel de Java PipedInputStream
- Le Tutoriel de Java OutputStream
- Le Tutoriel de Java ObjectOutputStream
- Le Tutoriel de Java PushbackInputStream
- Le Tutoriel de Java SequenceInputStream
- Le Tutoriel de Java BufferedInputStream
- Le Tutoriel de Java Reader
- Le Tutoriel de Java Writer
- Le Tutoriel de Java FileReader
- Le Tutoriel de Java FileWriter
- Le Tutoriel de Java CharArrayReader
- Le Tutoriel de Java ByteArrayInputStream
- Le Tutoriel de Java DataInputStream
- Le Tutoriel de Java ObjectInputStream
- Le Tutoriel de Java InputStreamReader
- Le Tutoriel de Java OutputStreamWriter
- Le Tutoriel de Java InputStream
- Le Tutoriel de Java FileInputStream
Show More