Le Tutoriel de Java InputStreamReader
1. InputStreamReader
InputStreamReader est une sous-classe de Reader, qui est un pont vous permettant de convertir un byte stream en un character stream. En d'autres termes, il vous permet de convertir un InputStream en un Reader.
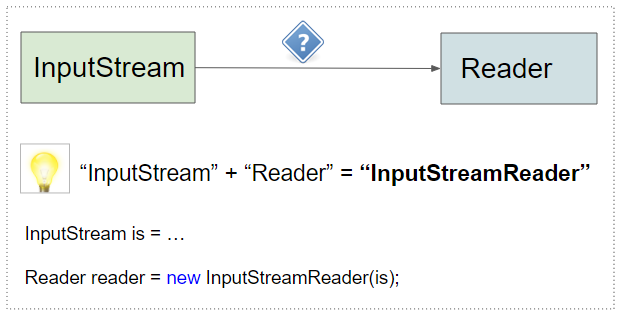
Astuce: Pour convertir un "InputStream" en "Reader", il suffit de concaténer ces deux mots pour former le mot "InputStreamReader" et vous obtiendrez la solution du problème.
InputStreamReader constructors
InputStreamReader(InputStream in)
InputStreamReader(InputStream in, String charsetName)
InputStreamReader(InputStream in, Charset cs)
InputStreamReader(InputStream in, CharsetDecoder dec)2. UTF-16 InputStreamReader
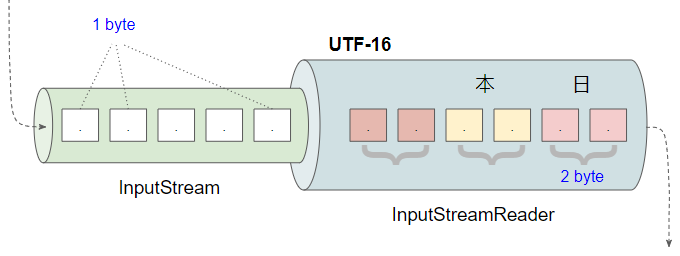
UTF-16 est un encodage pratiquement courant pour le texte chinois ou japonais. Dans cet exemple, on analyse la manière dont InputStreamReader lit les textes UTF-16.
Tout d'abord, observer le fichier texte japonais ci-dessous, qui est encodé en UTF-16.
utf16-file-with-bom.txt
JP日本-八洲Le code complet de l'exemple:
InputStreamReader_UTF16_Ex1.java
package org.o7planning.inputstreamreader.ex;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
public class InputStreamReader_UTF16_Ex1 {
// A file in UTF-16.
private static final String fileURL = "https://s3.o7planning.com/txt/utf16-file-with-bom.txt";
public static void main(String[] args) throws MalformedURLException, IOException {
System.out.println(" --- Characters in Character Stream (InputStreamReader) ---");
readAs_UTF16_Character_Stream();
System.out.println();
System.out.println(" --- Bytes in UTF-16 file ---");
readAs_Binary_Stream();
}
private static void readAs_UTF16_Character_Stream() throws MalformedURLException, IOException {
InputStream is = new URL(fileURL).openStream();
InputStreamReader isr = new InputStreamReader(is, "UTF-16");
int charCode;
while ((charCode = isr.read()) != -1) { // Read each character.
System.out.println((char) charCode + " " + charCode);
}
isr.close();
}
private static void readAs_Binary_Stream() throws MalformedURLException, IOException {
InputStream is = new URL(fileURL).openStream();
int byteValue;
while ((byteValue = is.read()) != -1) { // Read each byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
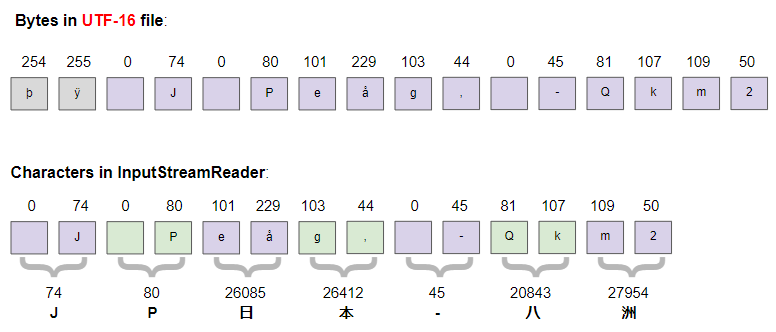
--- Characters in Character Stream (InputStreamReader) ---
J 74
P 80
日 26085
本 26412
- 45
八 20843
洲 27954
--- Bytes in UTF-16 file ---
þ 254
ÿ 255
0
J 74
0
P 80
e 101
å 229
g 103
, 44
0
- 45
Q 81
k 107
m 109
2 50Créer un objet InputStreamReader avec un encodage UTF-16 et envelopper un objet InputStream:
String url = "https://s3.o7planning.com/txt/utf16-file-with-bom.txt";
InputStream is = new URL(url).openStream();
InputStreamReader isr = new InputStreamReader(is, "UTF-16");L'image ci-dessous montre les bytes dans le fichier UTF-16. Les deux premiers bytes (254, 255) sont utilisés pour marquer le début d'un texte UTF-16.
InputStreamReader UTF-16 lit les 2 premiers bytes pour déterminer l'encodage du texte et pour comprendre qu'il fonctionne avec un texte UTF-16. Il joint 2 bytes consécutifs pour former un caractère ...
3. UTF-8 InputStreamReader
UTF-8 est l'encodage le plus populaire au monde, qui peut coder toutes les écritures dans le monde, y compris les caractères chinois et japonais. On analyse la manière dont InputStreamReader lit les textes UTF-8.
Tout d'abord, observer le fichier texte japonais ci-dessous, qui est encodé en UTF-8:
utf8-file-without-bom.txt
JP日本-八洲Le code complet de l'exemple:
InputStreamReader_UTF8_Ex1.java
package org.o7planning.inputstreamreader.ex;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
public class InputStreamReader_UTF8_Ex1 {
// A file with UTF-8 encoding (And without BOM (Byte Order Mark)).
private static final String fileURL = "https://s3.o7planning.com/txt/utf8-file-without-bom.txt";
public static void main(String[] args) throws MalformedURLException, IOException {
System.out.println(" --- Characters in Character Stream (InputStreamReader) ---");
readAs_UTF8_Character_Stream();
System.out.println();
System.out.println(" --- Bytes in UTF-8 file ---");
readAs_Binary_Stream();
}
private static void readAs_UTF8_Character_Stream() throws MalformedURLException, IOException {
InputStream is = new URL(fileURL).openStream();
InputStreamReader isr = new InputStreamReader(is, "UTF-8");
int charCode;
while ((charCode = isr.read()) != -1) { // Read each character.
System.out.println((char) charCode + " " + charCode);
}
isr.close();
}
private static void readAs_Binary_Stream() throws MalformedURLException, IOException {
InputStream is = new URL(fileURL).openStream();
int byteValue;
while ((byteValue = is.read()) != -1) { // Read each byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Characters in Character Stream (InputStreamReader) ---
J 74
P 80
日 26085
本 26412
- 45
八 20843
洲 27954
--- Bytes in UTF-8 file ---
J 74
P 80
æ 230
151
¥ 165
æ 230
156
¬ 172
- 45
å 229
133
« 171
æ 230
´ 180
² 178Créer un objet InputStreamReader avec un encodage UTF-8 et envelopper un objet InputStream:
String url = "https://s3.o7planning.com/txt/utf8-file-without-bom.txt";
InputStream is = new URL(url).openStream();
InputStreamReader isr = new InputStreamReader(is, "UTF-8");L'image ci-dessous montre les bytes dans le fichier UFT-8:
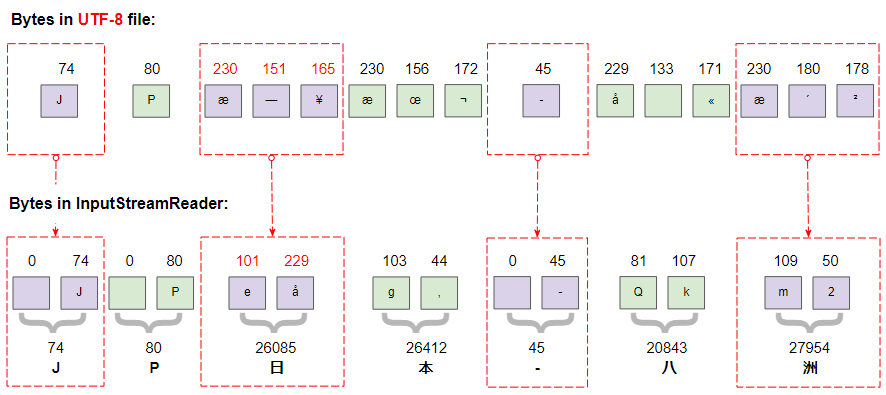
L'encodage UTF-8 est beaucoup plus compliqué que UTF-16. Il faut 1, 2, 3 ou 4bytes pour stocker un caractère. Cela dépend du code du caractère.
Number of bytes | From | To | Byte 1 | Byte 2 | Byte 3 | Byte 4 | ||
1 | U+0000 | 0 | U+007F | 127 | 0xxxxxxx | |||
2 | U+0080 | 128 | U+07FF | 2047 | 110xxxxx | 10xxxxxx | ||
3 | U+0800 | 2048 | U+FFFF | 65535 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
4 | U+10000 | 65536 | U+10FFFF | 1114111 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
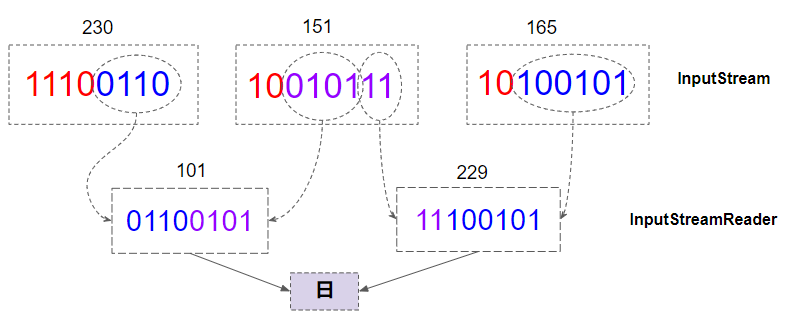
L'image ci-dessous est un exemple qui illustre la manière dont UTF-8 InputStreamReader transforme 3 bytes d'UTF-8 en un caractère de 2 bytes de Java:
Tutoriels Java IO
- Le Tutoriel de Java CharArrayWriter
- Le Tutoriel de Java FilterReader
- Le Tutoriel de Java FilterWriter
- Le Tutoriel de Java PrintStream
- Le Tutoriel de Java BufferedReader
- Le Tutoriel de Java BufferedWriter
- Le Tutoriel de Java StringReader
- Le Tutoriel de Java StringWriter
- Le Tutoriel de Java PipedReader
- Le Tutoriel de Java LineNumberReader
- Le Tutoriel de Java PushbackReader
- Le Tutoriel de Java PrintWriter
- Tutoriel sur les flux binaires Java IO
- Le Tutoriel de Java IO Character Streams
- Le Tutoriel de Java BufferedOutputStream
- Le Tutoriel de Java ByteArrayOutputStream
- Le Tutoriel de Java DataOutputStream
- Le Tutoriel de Java PipedInputStream
- Le Tutoriel de Java OutputStream
- Le Tutoriel de Java ObjectOutputStream
- Le Tutoriel de Java PushbackInputStream
- Le Tutoriel de Java SequenceInputStream
- Le Tutoriel de Java BufferedInputStream
- Le Tutoriel de Java Reader
- Le Tutoriel de Java Writer
- Le Tutoriel de Java FileReader
- Le Tutoriel de Java FileWriter
- Le Tutoriel de Java CharArrayReader
- Le Tutoriel de Java ByteArrayInputStream
- Le Tutoriel de Java DataInputStream
- Le Tutoriel de Java ObjectInputStream
- Le Tutoriel de Java InputStreamReader
- Le Tutoriel de Java OutputStreamWriter
- Le Tutoriel de Java InputStream
- Le Tutoriel de Java FileInputStream
Show More