Utiliser Java Jsoup pour analyser HTML
1. Qu'est-ce que Jsoup?
Jsoup est Java HTML Parser. Jsoup est une bibliothèque utilisée pour parsemer des données du document HTML. Jsoup fournit des API qui sont utilisés pour extraire et manipuler des données venant de URL ou du fichier HTML. Elle utilise des méthodes similaires que celles de DOM, CSS , JQuery pour récupérer et manipuler des données.

Observez un exemple avec Jsoup:
HelloJsoup.java
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class HelloJsoup {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}2. La bibliothèuqe Jsoup
Vous pouvez utiliser Maven ou télécharger la bibliothèque Jsoup sous forme du fichier jar.
L'utilisation maven:
<!-- http://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>Ou téléchargement:
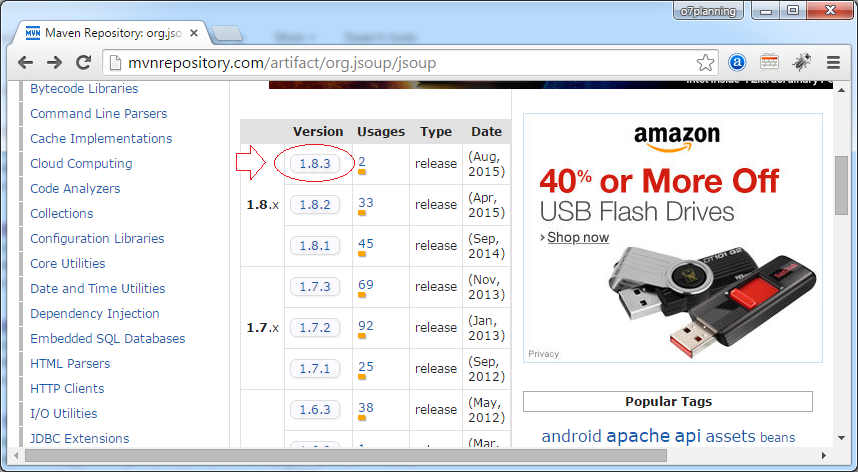
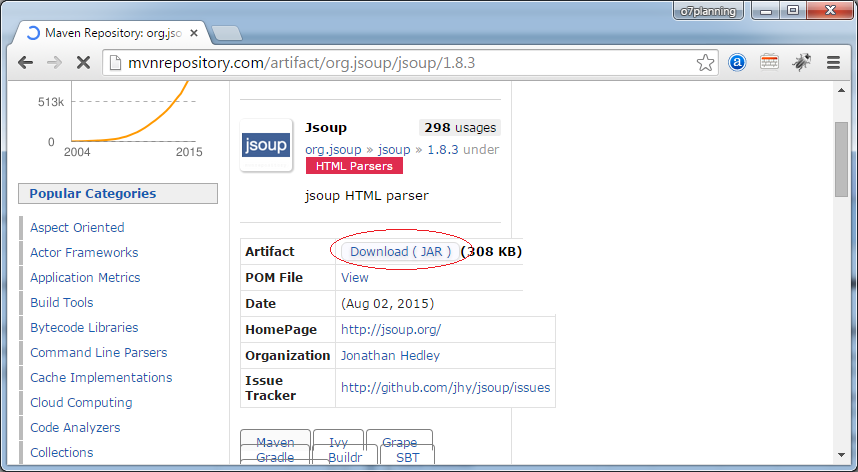
3. Jsoup API
Jsoup comprend plusieurs de classes, mais il y a 3 classes les plus importantes, ce sont:
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Jsoup.java
Méthode | Description |
static Connection connect(String url) | Crée et renvoie Connection de URL. |
static Document parse(File in, String charsetName) | Analyse le fichier HTML avec charset spécifié dans le document. |
tatic Document parse(File in, String charsetName, String baseUri) | Analyse le document HTML avec charset spécifié, et baseUri. |
static Document parse(String html) | Analyse le code HTML donné et renvoie Document. |
static Document parse(String html, String baseUri) | Analyse le code HTML donné avec baseUri en Document. |
static Document parse(URL url, int timeoutMillis) | Analyse le URL donné en Document. |
static String clean(String bodyHtml, Whitelist whitelist) | Renvoie un HTML sécurisé à partir du HTML d'entré, en analysant HTML d'entré et en le filtrant dans une liste blanche (Whitelist) des étiquettes et des attributs autorisés. |
- Document.java
Méthodes | Description |
Element body() |
Accède aux éléments body du document HTML |
Charset charset() |
Renvoie charset utilisé dans ce document
|
void charset(Charset charset) |
Définit charset utilisé dans ce document.
|
Document clone() |
Crée une copy autonome et profonde de ce node et de tous ses enfants.
|
Element createElement(String tagName) | Crée un nouveau élément |
static Document createShell(String baseUri) |
Crée une coquille vide et valide d'un document (Document), appropriée pour ajouter plus d'éléments à.
|
Element head() |
Accède aux éléments head du document.
|
String location() |
Renvoie URL de ce document.
|
String nodeName() |
Renvoie le nom du noeud de ce node.
|
Document normalise() |
Normalise ce document.
|
String outerHtml() |
Renvoie Outer HTML de ce node.
|
Document.OutputSettings outputSettings() |
Obtient les paramètres de sortie actuels du document.
|
Document outputSettings(Document.OutputSettings outputSettings) |
Définit les paramètres de sortie actuels du document.
|
Document.QuirksMode quirksMode() | |
Document quirksMode(Document.QuirksMode quirksMode) | |
Element text(String text) |
Définit le contenu du texte (text) du body de ce document.
|
String title() |
Obtient le contenu de la chaîne de l'élément de titre du document.
|
void title(String title) |
Définit l'élément du titre du document.
|
boolean updateMetaCharsetElement() |
Renvoie true si l'élément (element) avec l'information charset dans ce document est mis à jour lors des modifications via la méthode Document.charset(Charset). |
void updateMetaCharsetElement(boolean update) |
Définit si l'élément (element) avec les informations charset dans ce document est mis à jour sur les modifications via Document.charset (Charset) ou non.
|
- Element.java
4. La manipultion avec Document
Créer le document à partir de URL
GetDocumentFromURL.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromURL {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}Exécution l'exemple:
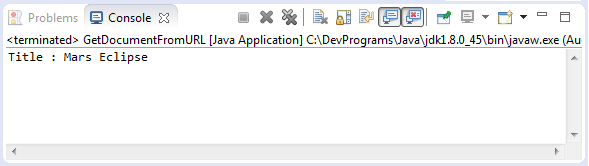
Create Document from File
GetDocumentFromFile.java
package org.o7planning.tutorial.jsoup.document;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromFile {
public static void main(String[] args) throws IOException {
File htmlFile = new File("C:/index.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
String title = doc.title();
System.out.println("Title : " + title);
}
}Create Document from String
GetDocumentFromString.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromString {
public static void main(String[] args) throws IOException {
String htmlString = "<html><head><title>Simple Page</title></head>"
+ "<body>Hello</body></html>";
Document doc = Jsoup.parse(htmlString);
String title = doc.title();
System.out.println("Title : " + title);
System.out.println("Content:\n");
System.out.println(doc.toString());
}
}Exécution l'exemple:
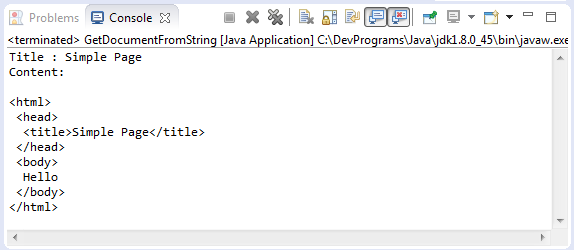
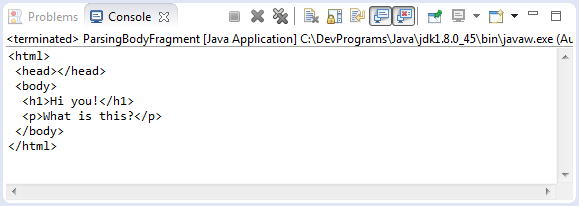
Analyse le fragment HTML
Un document complet HTML comprend la tête et le corps, parfois vous devez analyser un fragment de HTML. Et vous pouvez prendre un document entier HTML qui comprend la tête et le corps. Observez l'exemple:
ParsingBodyFragment.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParsingBodyFragment {
public static void main(String[] args) throws IOException {
String htmlFragment = "<h1>Hi you!</h1><p>What is this?</p>";
Document doc = Jsoup.parseBodyFragment(htmlFragment);
String fullHtml = doc.html();
System.out.println(fullHtml);
}
}Exécution l'exemple:
5. Les méthodes DOM
Jsoup a quelques méthodes similaires de celles dans le modèle DOM (un modèle pour analyser le document XML)
Méthodes | Description |
Element getElementById(String id) | Trouver un élément par ID, y compris ou sous cet élément. |
Elements getElementsByTag(String tag) | Trouver des éléments, y compris et récursivement sous cet élément, avec le nom de la marque spécifiée. |
Elements getElementsByClass(String className) | Trouver des éléments qui ont cette classe classNam, y compris ou sous cet élément. |
Elements getElementsByAttribute(String key) | Trouver des éléments qui ont un ensemble d'attributs nommé. Le cas insensible |
Elements siblingElements() | Obtenir des éléments fraternels. |
Element firstElementSibling() | Obtenir le premier élément fraternel de cet élément. |
Element lastElementSibling() | Renvoyer le dernier élément frère de cet élément. |
...... | |
Les méthodes de l'extraction des données de Element.
Méthode | Description |
String attr(String key) | Obtenir la valeur d'un attribut par sa clé. |
void attr(String key, String value) | Définir un attribut. Si l'attribut existe déjà, il est remplacé. |
String id() | Renvoyer l'attribut ID, s'il existe, ou une chaîne vide si non. |
String className() | Obtenir la valeur littérale de l'attribut "class" de cet élément, qui peut inclure plusieurs noms de classe, espace séparé. (Par exemple <div class="header gray"> renvoie "header gray") |
Set<String> classNames() | Renvoyer tous les noms de la classe. Par exemple <div class="header gray">, renvoie un ensemble de 2 éléments "header" et "gray". Notez que les modifications sur cet ensemble ne changent pas l'attribut de l'élément. Utilisez la méthode classNames(java.util.Set) pour la persister. |
String text() | Obtenir le texte combiné de cet élément et de tous ses enfants |
void text(String value) | Définir le texte de cet élément. |
String html() | Récupérer le HTML interne de l'élément. Par exemple <div><p>a</p> renvoie <p>a</p>. (Node.outerHtml() renverra <div><p>a</p></div>.) |
void html(String value) | Définir le Html interne dans cet élément. Supprimer le HTML existant déjà. |
Tag tag() | Obtenir l'étiquette de l'élément. |
String tagName() | Obtenir le nom de l'étiquette de cet élément. Par exemple div. |
...... | |
Les méthodes pour manipuler HTML:
Méthodes | Description |
Element append(String html) | Ajouter un HTML interne à cet élément. Le HTML fourni sera analysé et chaque nœud sera ajouté à la fin des enfants. |
Element prepend(String html) | Ajouter un HTML interne dans cet élément. Le HTML fourni sera analysé et chaque noeud sera ajouté du début des enfants de l'élément. |
Element appendText(String text) | Créer et ajouter un nouveau TextNode à cet élément. |
Element prependText(String text) | Créer et ajouter un nouveau TextNode à cet élément. |
Element appendElement(String tagName) | Créer un nouvel élément par nom de l'étiquette et ajouter-le comme dernier enfant. |
Element prependElement(String tagName) | Créer un nouvel élément par nom de l'étiquette et ajouter-le comme premier enfant. |
Element html(String value) | Définir le html interne dans cet élément. Effacer tous les Html existant en premier. |
...... | |
Par exemple, l'utilisation les méthodes de DOM, l'analyse d'un document HTML et extraire l'information dans le tag form.
register.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register</title>
</head>
<body>
<form id="registerForm" action="doRegister" method="post">
<table>
<tr>
<td>User Name</td>
<td><input type="text" name="userName" value="Tom" /></td>
</tr>
<tr>
<td>Password</td>
<td><input type="password" name="password" value="Tom001" /></td>
</tr>
<tr>
<td>Email</td>
<td><input type="email" name="email" value="theEmail@gmail.com" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" name="submit" value="Submit" /></td>
</tr>
</table>
</form>
</body>
</html>ReadHtmlForm.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
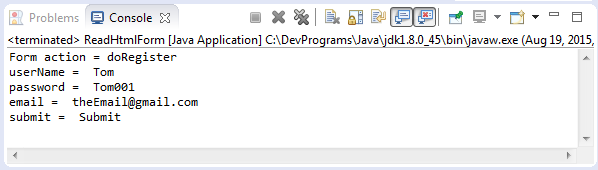
public class ReadHtmlForm {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("files/register.html"), "utf-8");
Element form = doc.getElementById("registerForm");
System.out.println("Form action = "+ form.attr("action"));
Elements inputElements = form.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println(key + " = " + value);
}
}
}Exécution l'exemple:
GetAllLinks.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
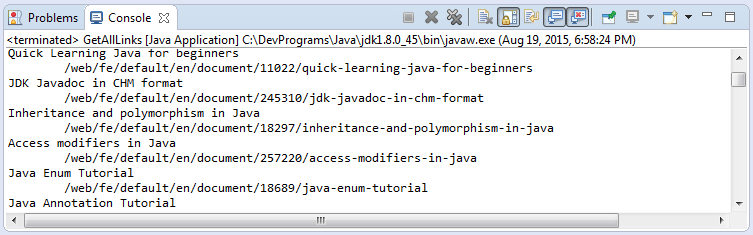
public class GetAllLinks {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://o7planning.org").get();
// Elements extends ArrayList<Element>.
Elements aElements = doc.getElementsByTag("a");
for (Element aElement : aElements) {
String href = aElement.attr("href");
String text = aElement.text();
System.out.println(text);
System.out.println("\t" + href);
}
}
}L'exécution de l'exemple:
6. Les méthodes similaires de Css, jQuery
Voulez- vous chercher ou manipuler des éléments qui utilisent la syntaxe similaire à CSS ou jQuery?
JSoup vous fournit quelques méthodes de réaliser cette tâche:
- Element.select(String selector)
- Elements.select(String selector)
Exemple:
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// a with href
Elements links = doc.select("a[href]");
// img with src ending .png
Elements pngs = doc.select("img[src$=.png]");
// div with class=masthead
Element masthead = doc.select("div.masthead").first();
// direct a after h3
Elements resultLinks = doc.select("h3.r > a");Les éléments JSoup vous supporte la syntaxe qui est similaire à CSS (ou JQuery) pour chercher des éléments correspondants. Celui-ci est si puissant et robuste. Les méthodes sélectionnées sont disponibles dans des classes Document, Element ou Elements.
Aperçu du Sélecteur (Selector).
Selecteur | Description |
tagname | Cherche des éléments par le tag. Par exemple: a |
ns|tag | Cherche des éléments par le tag dans un espace- nom (namespace), par exemple fb|name signifie de chercher des éléments <fb:name> |
#id | Cherche des éléments par ID, par exemple #logo |
.class: | Cherche des éléments par la classe, par exemple .masthead |
[attribute] | Des éléments avec un attribut, par exemple [href] |
[^attr] | Des éléments avec le préfixe du nom d'un attribut, par exemple [^data-] cherche des éléments avec des attributs qui commencent par data- |
[attr=value] | Des éléments avec la valeur d'attribut , par exemple [width=500] (utilise également la citation comme la séquence" ) |
[attr^=value], [attr$=value], [attr*=value] | Des éléments avec des valeurs d'attribut qui commence, finit par, ou comprend une valeur, par exemple [href*=/path/] |
[attr~=regex] | Des valeurs avec des valeurs d'attribut qui correspond l'expression régulière, par exemple img[src~=(?i)\.(png|jpe?g)] |
* | Tous les éléments, par exemple * |
Des combinaisons du secteur
Sélecteur | Description |
el#id | Des éléments avec ID, par exemple div#logo |
el.class | Des éléments avec la classe, par exemple div.masthead |
el[attr] | Des éléments avec attribut, par exemple a[href] |
N'importe quelle combinaison, par exemple a[href].highlight | |
ancestor child | (Des éléments enfant qui descend de l'aïeul) Des éléments enfant d'un élément, par exemple. .body p cherche des éléments p quiconques sous un bloc avec la classe "body" |
parent > child | Des éléments enfant qui descend directement de parent, par exemple div.content > p cherche des éléments p- est l'enfant direct de div ayant la classe ='content'; et body > * cherche des éléments enfant direct du tag body |
siblingA + siblingB | Cherche l' élément frère B précède immédiatement de l'événement A, par exemple div.head + div |
siblingA ~ siblingX | Cherche l' élément frère X précède l'élément A, par exemple h1 ~ p |
el, el, el | Le groupe multiple sélecteur, cherche des éléments qui correspondent à n'importe quel sélecteur; par exemple div.masthead, div.logo |
Pseudo selectors
Sélecteur | Description |
:lt(n) | Cherche les éléments dont l'indice fraternel (par exemple ses locations se trouve dans l'arbre DOM relative avec ses parents) est inférieur à n; par exemple td:lt(3) |
:gt(n) | Cherche les éléments dont l'indice fraternel est supérieur à n, par exemple div p:gt(2) |
:eq(n) | Cherche les éléments dont l'indice fraternel est égal à n; par exemple. form input:eq(1) |
:has(seletor) | Cherche les éléments qui comprennent des éléments correspondants au sélecteur; par exemple div:has(p) |
:not(selector) | Cherche les éléments qui ne correspondent pas au sélecteur; par exemple: div:not(.logo) |
:contains(text) | Cherche les éléments qui comprennnent le texte donné. La recherche est insensible à la casse; par exemple p:contains(jsoup) |
:containsOwn(text) | Cherche les éléments qui comprennent directement le texte donné |
:matches(regex) | Cherche les éléments dont le texte correspond l'expression régulière spécifique; par exemple div:matches((?i)login) |
:matchesOwn(regex) | Cherche les éléments dont le texte propre correspond l'expression régulière spécifique; |
Notez que les pseudo-sélecteurs indexés ci-dessus sont basés sur 0, c'est-à-dire que le premier élément est à l'index 0, le second à 1, et ,.. | |
QueryLinks.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QueryLinks {
public static void main(String[] args) throws IOException {
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Query <a> elements, href contain /document/
String cssQuery = "a[href*=/document/]";
Elements elements= doc.select(cssQuery);
Iterator<Element> iterator = elements.iterator();
while(iterator.hasNext()) {
Element e = iterator.next();
System.out.println(e.attr("href"));
}
}
}Les résultats:
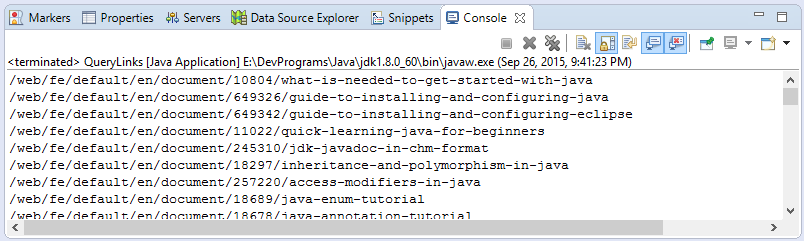
document.html
<html>
<head>
<title>Jsoup Example</title>
</head>
<body>
<h1>Java Tutorial For Beginners</h1>
<br>
<div id="content">
Content ....
</div>
<div class="related-container">
<h3>Related Documents</h3>
<a href="http://o7planning.org/web/fe/default/en/document/649342/guide-to-installing-and-configuring-eclipse">
Guide to Installing and Configuring Eclipse
</a>
<a href="http://o7planning.org/web/fe/default/en/document/649326/guide-to-installing-and-configuring-java">
Guide to Installing and Configuring Java
</a>
<a href="http://o7planning.org/web/fe/default/en/document/245310/jdk-javadoc-in-chm-format">
Jdk Javadoc in chm format
</a>
</div>
</body>
</html>SelectorDemo1.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SelectorDemo1 {
public static void main(String[] args) throws IOException {
File htmlFile = new File("document.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
// First <div> element has class ="related-container"
Element div = doc.select("div.related-container").first();
// List the <h3>, the direct child elements of the current element.
Elements h3Elements = div.select("> h3");
// Get first <h3> element
Element h3 = h3Elements.first();
System.out.println(h3.text());
// List <a> elements, is a descendant of the current element
Elements aElements = div.select("a");
// Query the current element list.
// The element that href contains 'installing'.
Elements aEclipses = aElements.select("[href*=Installing]");
Iterator<Element> iterator = aEclipses.iterator();
while (iterator.hasNext()) {
Element a = iterator.next();
System.out.println("Document: "+ a.text());
}
}
}Les résultats:
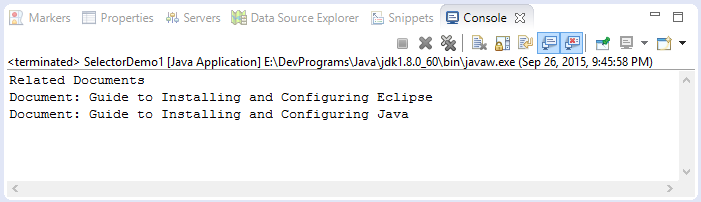
Tutoriels Java Open Source Libraries
- Le Tutoriel de Java JSON Processing API (JSONP)
- Utilisation de l'API Java Scribe OAuth avec Google OAuth2
- Obtenir des informations sur le matériel dans l'application Java
- Restfb Java API pour Facebook
- Créer Credentials pour Google Drive API
- Le Tutoriel de Java JDOM2
- Le Tutoriel de Java XStream
- Utiliser Java Jsoup pour analyser HTML
- Récupérer des informations géographiques basées sur l'adresse IP à l'aide de GeoIP2 Java API
- Lire et écrire un fichier Excel en Java à l'aide d'Apache POI
- Explorer le Facebook Graph API
- Manipulation de fichiers et de dossiers sur Google Drive à l'aide de Java
Show More